
Behind the Scenes: A Look at Rebuilding Our Schedule with Project Serena
-

-
By Andre Azzolini
Former Lead Engineer at Float

The Float September update included a brand new version of our schedule page, which we built entirely in React Hooks. We're pulling the curtain back in this post to explore our rationale and motivation for the rewrite, explain the technical challenges we encountered, and take a closer look at a few of our custom Hooks.
We love simplicity—it's one of our core values and a key driver of both product and engineering decisions. Unfortunately, product simplicity often results in engineering complexity: new features, heuristics, and edge cases often break existing abstractions, requiring more layers and workarounds. Over time, performance starts to suffer, and the codebase becomes harder to work in. Did someone say tech debt?
There's an upside, though—each of those layers and workarounds was added to solve a previously unknown problem. Converting unknown problems into known problems is the best way to understand a domain more completely, which is fundamental in designing less leaky abstractions.
After introducing project view in May, we decided it was time to revisit our architecture, simplify things, and prepare for the future. Specifically, we wanted to improve scroll performance and centralize our business-logic code.
While we began the initial planning at our engineering meetup in Miami, the project didn't truly come together until we decided on a code name for it. Our CEO, Glenn, had the winning suggestion: "How about Serena? A best in class athlete, powerful, multi-dimensional; a vocal leader,"—attributes to strive for both on and off the court.
#AusOpen pic.twitter.com/7n7qXLo00S
— Serena Williams (@serenawilliams) January 21, 2019
Silky smooth scrolling
Scrolling is crucial for app responsiveness—so important, in fact, that modern browsers handle scrolling in a separate thread from JavaScript execution for performance. This works great until you need to synchronize something based on scroll position. In our case, we needed to keep the first row and column pinned on the screen, leaving us with just two options (each with its own downside):
- Hijack scrolling and set all positions manually
- Asynchronously respond to scroll position updates and update the fixed headers
With the first option, you couple the two threads, which eliminates the browser performance improvements and results in laggy scrolling. With the second option, scrolling feels native, but the updates lag behind, resulting in unsynchronized grid lines while scrolling.
There's some good news, though—the modern CSS3 position: sticky feature enables the browser to synchronize the fixed headers without JavaScript; we get both fast native scrolling and synchronized grid lines. Unfortunately, this isn't supported by IE11, but we determined that was a reasonable price to pay for increased responsiveness.
Secondly, in Float, the height of a given person row depends on whether or not they have overtime scheduled in the near past or future, meaning that as you scroll left and right, the height of a given row may change. To complicate things further, if you've scrolled down a bit and then scroll horizontally, we want to keep the first visible row's position static (what we call the "anchor" row), even if the height of rows above have changed.
Finally, the ability to scroll infinitely makes rendering everything at once untenable. Virtualization (aka windowing) is a technique for detecting what should be on screen and only rendering what's necessary. Although several great windowing libraries exist for React, none were a perfect fit for our requirements. We wanted full control of the scrolling experience, and so we opted to build our own windowing system.
Enter our first main Hook, useWindow.
useWindow's job is to monitor the scroll position, render the minimum set of visible components into the React tree, and ensure the anchor row doesn't visually shift. A second hook, useInfiniteSizerEffect, is responsible for detecting the proximity of the current scroll position to the loaded edges and extending the week range appropriately. Disabling infinite sizing is as simple as removing one line of code, and this was the first inkling of proof that using Hooks can indeed result in more decoupled code. This was confirmed by a third hook, useAutoscroll, which facilitates dragging something to a date that's out of the viewable range—again, a single line.
To ensure our windowing library was performing well, we mocked high volumes of data and made heavy use of the Chrome devtools profiler to identify and fix hotspots. The new React Developer Tools extension was also very valuable for identifying unnecessary renders and guiding us towards correct memoization—after all, there's nothing faster than code that doesn't execute!
Once we were confident our prototype was on the right track, it was time to bring it into our main application and start integrating with data in our Redux stores.
Enter our second main Hook.
DB to screen
One of the key goals from the Miami meetup was to define a solid view model for the schedule grid. We knew rows should be split, but there were two options for the vertical split: days or weeks.
Although days was a tempting and intuitive choice, lessons learned from past iterations guided us towards weeks, as it's closer to the visual representation on screen, and having fewer items ends up being more performant for windowing. We call each of these person-week blocks a Cell, and the next step was defining the process to transform database rows into the items that appear in each Cell.
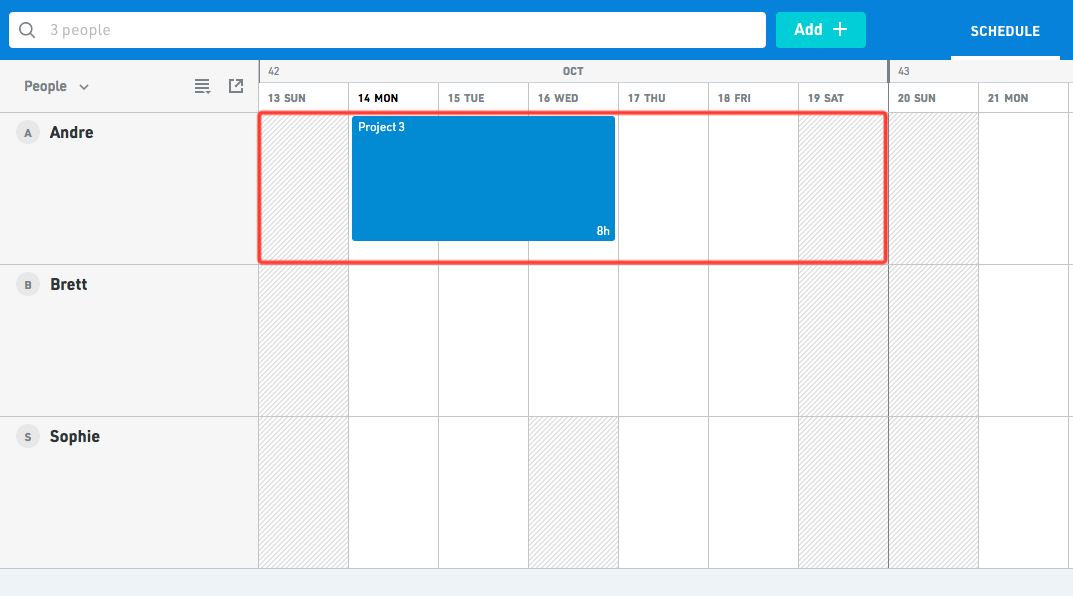
As network fetches and WebSocket updates flow into our central Redux data store, we want to reflect those changes on the schedule. The naive approach of fully rebuilding all Cells on each change falls apart with any type of volume, which means tracking two relationships:
- When an entity (e.g., a task) changes, which Cells need to be rebuilt?
- When rebuilding a Cell, which entities need to be considered?
Calculating those links is prohibitively expensive to do in real time, which means we need to introduce a cache. Cache invalidation is famously one of two hard problems in Computer Science, so we were careful to limit the scope, and ended up with a bidirectional map that stores:
- entity --> array of applicable Cell keys
- Cell key --> array of applicable entity ids
With this cache, processing any update is a safe and contained operation:
- Find all previously relevant cell keys for an entity (if any)
- Update the entity
- Find all newly relevant cell keys for that entity (if any)
- Update the cache to the new values
- Rebuild the relevant Cells
useCells is a function that combines useReducer with the above steps to return an object containing all schedule Cells. As our Redux state changes, useCells will receive LOAD_DATA events, and the necessary Cells will be rebuilt. The only way to change the rendered schedule is through this reducer, and there's a single function responsible for aggregating all relevant entities and building a Cell.
Constraints can be counter-intuitively empowering; having a single code path for rendering a Cell ensures consistency, makes code navigation easy, and simplifies testing.
User interactions with the schedule also go through useCells. For example, if the user dragged a task to the right, we might dispatch:
dispatch({
type: 'DRAG_ENTITY',
items: [<the task entity>],
dayDelta: 3,
rowId: 'person-123',
});
The DRAG_ENTITY handler houses our core business logic. Dragging a task three days to the right might mean the task gets shifted seven days if there is a holiday or time off scheduled. We leverage the bidirectional maps here as well to ensure we're considering all other potentially relevant entities without needing to scan through every entity in the system.
Additionally, decoupling DOM interactions (user moused down and dragged 80 pixels to the right) and a discrete modification description (the dispatch above) means that we can unit test our core business logic without a UI at all (using react-hooks-testing-library), which is super valuable. It also means we can share the logic on other platforms like our React Native iOS and Android apps—we just have to write a translation from touch events to actions.
Game, set, match
With the core architecture in place, the remaining work was porting over interactions and edge cases. We tweaked behavior opportunistically (such as split preview) and took the time to add more tests and documentation along the way.
Working with Hooks was a joy, and left us with a more modular codebase that's easy to work in and easy to test. Tracking re-renders from useEffect was straightforward, and there was always a clear path to prevent unnecessary ones via memoization.
Although it's usually wise to heed the traditional advice against rewrites, it's not an absolute rule, especially when you have a more complete understanding of the problem domain. While I wouldn't suggest rewriting existing class-based components into Hooks for the sheer sake of it, I also can't imagine us ever going back.
Get exclusive monthly updates on the best tools and productivity tips for asynchronous remote work
Join 100,000+ readers globally


