
React - The Missing Parts

Question the rules for fun and profit
One of the nice things about having your own lean copy of a popular library's patterns is that you can experiment with all sorts of changes.
In my case, I have a React-clone, Live, which includes all the familiar basics: props, state and hooks. The semantics are all the same. The premise is simple: after noticing that React is shaped like an incremental, resumable effect system, I wanted to see if I could use the same patterns for non-UI application code too.
Thus, my version leaves out the most essential part of React entirely: actually rendering to HTML. There is no React-DOM as such, and nothing external is produced by the run-time. Live Components mainly serve to expand into either other Live Components, or nothing. This might sound useless, but it turns out it's not.
I should emphasize though, I am not talking about the React useEffect hook. The Effect-analog in React are the Components themselves.
Along the way, I've come up with some bespoke additions and tweaks to the React API, with some new ergonomics. Together, these form a possible picture of React: The Missing Parts that is fun to talk about. It's also a trip to a parallel universe where the React team made different decisions, subject to far less legacy constraints.
On the menu:
- No-hooks and Early Return
- Component Morphing
useMemovsuseEffect + setState- and some wild Yeet-Reduce results

Break the Rules
One of the core features of contemporary React is that it has rules. Many are checked by linters and validated at run-time (in dev mode). You're not allowed to break them. Don't mutate that state. Don't skip this dependency.
Mainly they are there to protect developers from old bad habits: each rule represents an entire class of UI bugs. These are easy to create, difficult to debug and even harder to fix. Teaching new React devs to stick to them can be hard, as they don't yet realize all the edge cases users will expect to work. Like for example, that external changes should be visible immediately, just like local changes.
Other rules are inherent limitations in how the React run-time works, which simply cannot be avoided. But some are not.
At its core, React captures an essential insight about incremental, resumable code: that ordinary arrays don't fit into such a model at all. If you have an array of some objects [A, B, C, D], which changes to an array [B*, A, E, D*, C], then it takes a slow deep diff to figure out that 4 elements were moved around, 2 of which were changed, and only 1 was added. If each element has a unique key and is immutable however, it's pretty trivial and fast.
Hence, when working incrementally, you pretty much always want to work with key/value maps, or some equivalent, not plain arrays.
Once you understand this, you can also understand why React hooks work the way they do. Hooks are simple, concise function calls that do one thing. They are local to an individual component, which acts as their scope.
Hooks can have a state, which is associated anonymously with each hook. When each hook is first called, its initial state is added to a list: [A, B, C, ...]. Later, when the UI needs to re-render, the previous state is retrieved in the same order. So you need to make the exact same calls each time, otherwise they would get the wrong state. This is why you can't call hooks from within if or for. You also can't decide to return early in the middle of a bunch of hook calls. Hooks must be called unconditionally.
If you do need to call a hook conditionally, or a variable number of times, you need to wrap it in a sub-component. Each such component instance is then assigned a key and mounted separately. This allows the state to be matched up, as separate nodes in the UI tree. The downside is that now it's a lot harder to pass data back up to the original parent scope. This is all React 101.
if (foo) {
const value = useMemo(..);
// ...
}
else {
useNoMemo(..);
}But there's an alternative. What if, in addition to hooks like useContext and useMemo, you had a useNoContext and useNoMemo?
When you call useNoMemo, the run-time can simply skip ahead by 1 hook. Graphics programmers will recognize this as shader-like control flow, where inactive branches are explicitly kept idle. While somewhat cumbersome to write, this does give you the affordance to turn hooks on or off with if statements.
However, a useNo... hook is not actually a no-op in all cases. It will have to run clean-up for the previous not-no-hook, and throw away its previous state. This is necessary to dispose of associated resources and event handlers. So you're effectively unmounting that hook.
This means this pattern can also enable early return: this should automatically run a no-hook for any hook that wasn't called this time. This just requires keeping track of the hook type as part of the state array.
Is this actually useful in practice? Well, early return and useNoMemo definitely is. It can mean you don't have to deal with null and if in awkward places, or split things out into subcomponents. On the other hand, I still haven't found a direct use for useNoState.
useNoContext is useful for the case where you wish to conditionally not depend on a context even if it has been provided upstream. This can selectively avoid an unnecessary dependency on a rapidly changing context.
The no-hook pattern can also apply to custom hooks: you can write a useNoFoo for a useFoo you made, which calls the built-in no-hooks. This is actually where my main interest lies: putting an if around one useState seems like an anti-pattern, but making entire custom hooks optional seems potentially useful. As an example, consider that Apollo's query and subscription hooks come with a dedicated skip option, which does the same thing. Early return is a bad idea for custom hooks however, because you could only use such a hook once per component, as the last call.
You can however imagine a work-around. If the run-time had a way to push and pop a new state array in place, starting from 0 anew, then you could safely run a custom hook with early return. Let's imagine such a useYolo:
// A hook
const useEarlyReturnHook = (...) => {
useMemo(...);
if (condition) return false;
useMemo(...);
return true;
}{
// Inside a component
const value1 = useYolo(() => useEarlyReturnHook(...));
const value2 = useYolo(() => useEarlyReturnHook(...));
}But that's not all. If you call our hotline now, you also get hooks in for-loops for free. Because a for-loop is like a repeating function with a conditional early return. So just wrap the entire for loop in useYolo, right?
Except, this is a really bad idea in most cases. If it's looping over data, it will implicitly have the same [A, B, C, D] to [B*, A, E, D*, C] matching problem: every hook will have to refresh its state and throw away caches, because all the input data has seemingly changed completely, when viewed one element at a time.
So while I did actually make a working useYolo, I ended up removing it again, because it was more footgun than feature. Instead, I tried a few other things.
Morph
One iron rule in React is this: if you render one type of component in place of another one, then the existing component will be unmounted and thrown away entirely. This is required because each component could do entirely different things.
<A> renders:
<C><B> renders:
<C>Logically this also includes any rendered children. If <A> and <B> both render a <C>, and you swap out an <A> with a <B> at run-time, then that <C> will not be re-used. All associated state will be thrown away, and any children too. If component <C> has no state at all, and the same props as before, this is 100% redundant. This applies to all flavors of "styled components" for example, which are just passive, decorated HTML elements.
One case where this is important is in page routing for apps. In this case, you have a <FooPage>, a <BarPage>, and so on, which likely look very similar. They both contain some kind of <PageLayout> and they likely share most of their navigation and sidebars. But because <FooPage> and <BarPage> are different components, the <PageLayout> will not be reused. When you change pages, everything inside will be rebuilt, which is pretty inefficient. The solution is to lift the <PageLayout> out somehow, which tends to make your route definitions very ugly, because you have to inline everything.
It's enough of a problem that React Router has redesigned its API for the 6th time, with an explicit solution. Now a <PageLayout> can contain an <Outlet />, which is an explicit slot to be filled with dynamic page contents. You can also nest layouts and route definitions more easily, letting the Router do the work of wrapping.
It's useful, but to me, this feels kinda backwards. An <Outlet /> serves the same purpose as an ordinary React children prop. This pattern is reinventing something that already exists, just to enable different semantics. And there is only one outlet per route. There is a simpler alternative: what if React could just keep all the children when it remounts a parent?
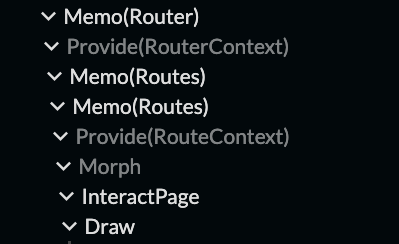
In Live, this is available on an opt-in basis, via a built-in <Morph> wrapper. Any component directly inside <Morph> will morph in-place when its type changes. This means its children can also be updated in place, as long as their type hasn't changed in turn. Or unless they are also wrapped in <Morph>.
So from the point of view of the component being morphed, it's a full unmount/remount... but from the point of view of the matching children, nothing is changing at all.
Implementing this was relatively easy, again a benefit of no-hooks and built-in early return which makes it easy to reset state. Dealing with contexts was also easy, because they only change at context providers. So it's always safe to copy context between two ordinary sibling nodes.
You could wonder if it makes sense for morphing to be the default behavior in React, instead of the current strict remount. After all, it shouldn't ever break anything, if all the components are written "properly" in a pure and functional way. But the same goes for memo(…)... and that one is still opt-in?
Making <Morph> opt-in also makes a lot of sense. It means the default is to err on the side of clean-slate reproducibility over performance, unless there is a reason for it. Otherwise, all child components would retain all their state by default (if compatible), which you definitely don't want in all cases.
For a <Router>, I do think it should automatically morph each routed page instead of remounting. That's the entire point of it: to take a family of very similar page components, and merge them into a single cohesive experience. With this one minor addition to the run-time, large parts of the app tree can avoid re-rendering, when they used to before.
You could however argue the API for this should not be a run-time <Morph>, but rather a static morph(…) which wraps a Component, similar to memo(…). This would mean that is up to each Component to decide whether it is morphable, as opposed to the parent that renders it. But the result of a static morph(…) would just be to always render a run-time <Morph> with the original component inside, so I don't think it matters that much. You can make a static morph(…) yourself in user-land.
Stateless
One thing React is pretty insistent about is that rendering should be a pure function. State should not be mutated during a render. The only exception is the initial render, where e.g. useState accepts a value to be set immediately:
const initialState = props.value.toString();
const [state, setState] = useState<T>(initialState);Once mounted, any argument to useState is always ignored. If a component wishes to mutate this state later, e.g. because props.value has changed, it must schedule a useEffect or useLayoutEffect afterwards:
useEffect(() => {
if (...) setState(props.value.toString());
}, [props.value])This seems simple enough, and stateless rendering can offer a few benefits, like the ability to defer effects, to render components concurrently, or to abort a render in case promises have not resolved yet.
In practice it's not quite so rosy. For one thing, this is also where widgets have to deal with parsing/formatting, validation, reconciling original and edited data, and so on. It's so much less obvious than the initialState pattern, that it's a typical novice mistake with React to not cover this case at all. Devs will build components that can only be changed from the inside, not the outside, and this causes various bugs later. You will be forced to use key as a workaround, to do the opposite of a <Morph>: to remount a component even if its type hasn't changed.
With the introduction of the hooks API, React dropped any official notion of "update state for new props", as if the concept was not pure and React-y enough. You have to roll your own. But the consequence is that many people write components that don't behave like "proper" React components at all.
If the state is always a pure function of a prop value, you're supposed to use a useMemo instead. This will always run immediately during each render, unlike useEffect. But a useMemo can't depend on its own previous output, and it can't change other state (officially), so it requires a very different way of thinking about derived logic.
From experience, I know this is one of the hardest things to teach. Junior React devs reach for useEffect + setState constantly, as if those are the only hooks in existence. Then they often complain that it's just a more awkward way to make method calls. Their mental model of their app is still a series of unique state transitions, not declarative state values: "if action A then trigger change B" instead of "if state A then result B".
Still, sometimes useMemo just doesn't cut it, and you do need useEffect + setState. Then, if a bunch of nested components each do this, this creates a new problem. Consider this artificial component:
const Test = ({value = 0, depth = 5}) => {
const [state, setState] = useState(value);
useEffect(() => {
setState(value);
}, [value])
if (depth > 1) return <Test value={state} depth={depth - 1} />;
return null;
}<Test value={0} /> expands into:
<Test value={0} depth={5}>
<Test value={0} depth={4}>
<Test value={0} depth={3}>
<Test value={0} depth={2}>
<Test value={0} depth={1} />
</Test>
</Test>
</Test>
</Test>Each will copy the value it's given into its state, and then pass it on. Let's pretend this is a real use case where state is actually meaningfully different. If a value prop changes, then the useEffect will change the state to match.
The problem is, if you change the value at the top, then it will not re-render 5 instances of Test, but 20 = 5 + 5 + 4 + 3 + 2 + 1.
Not only is this an N2 progression in terms of tree depth, but there is an entire redundant re-render right at the start, whose only purpose is to schedule one effect at the very top.
That's because each useEffect only triggers after all rendering has completed. So each copy of Test has to wait for the previous one's effect to be scheduled and run before it can notice any change of its own. In the mean time it continues to re-render itself with the old state. Switching to the short-circuited useLayoutEffect doesn't change this.
In React, one way to avoid this is to wrap the entire component in memo(…). Even then that will still cause 10 = 5x2 re-renders, not 5: one to schedule the effect or update, and another to render its result.
Worse is, if Test passes on a mix of props and state to children, that means props will be updated immediately, but state won't. After each useEffect, there will be a different mix of new and old values being passed down. Components might act weird, and memo() will fail to cache until the tree has fully converged. Any hooks downstream that depend on such a mix will also re-roll their state multiple times.
This isn't just a rare edge case, it can happen even if you have only one layer of useEffect + setState. It will render things nobody asked for. It forces you to make your components fully robust against any possible intermediate state, which is a non-trivial ask.
To me this is an argument that useEffect + setState is a poor solution for having state change in response to props. It looks deceptively simple, but it has poor ergonomics and can cause minor re-rendering catastrophes. Even if you can't visually see it, it can still cause knock-on effects and slowdown. Lifting state up and making components fully controlled can address this in some cases, but this isn't a panacea.
Unintuitively, and buried in the docs, you can call a component's own setState(...) during its own render—but only if it's wrapped in an if to avoid an infinite loop. You also have to manually track the previous value in another useState and forego the convenient ergonomics of [...dependencies]. This will discard the returned result and immediately re-render the same component, without rendering children or updating the DOM. But there is still a double render for each affected component.
The entire point of something like React is to batch updates across the tree into a single, cohesive top-down data flow, with no redundant re-rendering cycles. Data ought to be calculated at the right place and the right time during a render, emulating the feeling of immediate mode UI.
Possibly a built-in useStateEffect hook could address this, but it requires that all such state is 100% immutable.
People already pass mutable objects down, via refs or just plain props, so I don't think "concurrent React" is as great an idea in practice as it sounds. There is a lot to be said for a reliable, single pass, top-down sync re-render. It doesn't need to be async and time-sliced if it's actually fast enough and memoized properly. If you want concurrency, manual fences will be required in practice. Pretending otherwise is naive.
My home-grown solution to this issue is a synchronous useResource instead, which is a useMemo with a useEffect-like auto-disposal ability. It runs immediately like useMemo, but can run a previous disposal function just-in-time:
const thing = useResource((dispose) => {
const thing = makeThing(...);
dispose(() => disposeThing(thing));
return thing;
}, [...dependencies]);This is particularly great when you need to set up a chain of resources that all have to have disposal afterwards. It's ideal for dealing with fussy derived objects during a render. Doing this with useEffect would create a forest of nullables, and introduce re-render lag.
Unlike all the previous ideas, you can replicate this just fine in vanilla React, as a perfect example of "cheating with refs":
const useResource = (callback, dependencies) => {
// Ref holds the pending disposal function
const disposeRef = useRef(null);
const value = useMemo(() => {
// Clean up prior resource
if (disposeRef.current) disposeRef.current();
disposeRef.current = null;
// Provide a callback to capture a new disposal function
const dispose = (f) => disposeRef.current = f;
// Invoke original callback
return callback(dispose);
}, dependencies);
// Dispose on unmount
// Note the double =>, this is for disposal only.
useEffect(() => () => {
if (disposeRef.current) disposeRef.current();
}, []);
return value;
}It's worth mentioning that useResource is so handy that Live still has no useEffect at all. I haven't needed it yet, and I continue to not need it. With some minor caveats and asterisks, useEffect is just useResource + setTimeout. It's a good reminder that useEffect exists because of having to wait for DOM changes. Without a DOM, there's no reason to wait.
That said, the notion of waiting until things have finished rendering is still eminently useful. For that, I have something else.
<Tree>
<Folder />
<Folder />
<Item />
</Tree><Tree>
<Folder>
<Item />
<Item />
</Folder>
<Folder>
<Folder />
<Item />
</Folder>
<Item />
</Tree>Yeet
Consider the following UI requirement: you want an expandable tree view, where you can also drag-and-drop items between any two levels.
At first this seems like a textbook use case for React, with its tree-shaped rendering. Only if you try to build it, you discover it isn't. This is somewhat embarrassing for React aficionados, because as the dated screenshot hints, it's not like this is a particularly novel concept.
In order to render the tree, you have to enumerate each folder recursively. Ideally you do this in a pure and stateless way, i.e. via simple rendering of child components.
Each component only needs to know how to render its immediate children. This allows us to e.g. only iterate over the Folders that are actually open. You can also lazy load the contents, if the whole tree is huge.
But in order to do the drag-and-drop, you need to completely flatten what's actually visible. You need to know the position of every item in this list, counting down from the tree root. Each depends on the contents of all the previous items, including whether their state is open or closed. This can only be determined after all the visible child elements have recursively been loaded and rendered, which happens long after <Tree> is done.
This is a scenario where the neat one-way data flow of React falls apart. React only allows for data to flow from parent to child during a render, not in the other direction.
If you wish to have <Tree> respond when a <Folder> or <Item> renders or changes, <Tree> has to set up a callback so that it can re-render itself from the top down. You can set it up so it receives data gathered during the previous render from individual Items:
<Tree> <––––.
<Folder> |
<Item /> ––˙
<Folder>
<Item />
<Item />
</Folder>
<Item />
</Folder>
</Tree>But, if you do this all "correctly", this will also re-render the originating <Item />. This will loop infinitely unless you ensure it converges to an inert new state.
If you think about it, it doesn't make much sense to re-run all of <Tree> from scratch just to respond to a child it produced. The more appropriate place to do so would be at </Tree>:
<Tree>
<Folder>
<Item /> –––.
<Folder> |
<Item /> |
<Item /> |
</Folder> |
<Item /> |
</Folder> |
</Tree> <–––––˙If Tree had not just a head, but also a tail, then that would be where it would resume. It would avoid the infinite loop by definition, and keep the data flow one-way.
If you squint and pretend this is a stack trace, then this is just a long-range yield statement... or a throw statement for non-exceptions... aka a yeet. Given that every <Item /> can yeet independently, you would then gather all these values together, e.g. using a map-reduce. This produces a single set of values at </Tree>, which can work on the lot. This set can be maintained incrementally as well, by holding on to intermediate reductions. This is yeet-reduce.
Also, there is no reason why </Tree> can't render new components of its own, which are then reduced again, and so on, something like:
<Tree>
<Folder>
<Item />
<Folder>
<Item />
<Item />
</Folder>
<Item />
</Folder>
</Tree>
|
˙–> <Resume>
<Row>
<Blank /> <Icon … /> <Label … />
</Row>
<Row>
<Collapse /> <Icon … /> <Label … />
</Row>
<Indent>
<Row>
<Blank /> <Icon … /> <Label … />
</Row>
<Row>
<Blank /> <Icon … /> <Label … />
</Row>
</Indent>
<Row>
<Blank /> <Icon … /> <Label … />
</Row>
</Resume>
If you put on your async/await goggles, then </Tree> looks a lot like a rewindable/resumable await Promise.all, given that the <Item /> data sources can re-render independently. Yeet-reduce allows you to reverse one-way data flow in local parts of your tree, flipping it from child to parent, without creating weird loops or conflicts. This while remaining fully incremental and react-y.
This may seem like an edge case if you think in terms of literal UI widgets. But it's a general pattern for using a reduction over one resumable tree to produce a new resumable tree, each having keys, and each being able to be mapped onto the next. Obviously it would be even better async and multi-threaded, but even single threaded it works like a treat.
Having it built into the run-time is a huge plus, which allows all the reductions to happen invisibly in the background, clearing out caches just-in-time. But today, you can emulate this in React with a structure like this:
<YeetReduce>
<Memo(Initial) context={context}>
<YeetContext.Provider value={context}>
...
</YeetContext.Provider>
</Memo(Initial)>
<Resume value={context.values}>
...
</Resume>
</YeetReduce>
Here, the YeetContext is assumed to provide some callback which is used to pass back values up the tree. This causes <YeetReduce> to re-render. It will then pass the collected values to Resume. Meanwhile Memo(Initial) remains inert, because it's memoized and its props don't change, avoiding an infinite re-rendering cycle.
This is mostly the same as what Live does, except that in Live the Memo is unnecessary: the run-time has a native concept of <Resume> (a fiber continuation) and tracks its dependencies independently in the upwards direction as values are yeeted.
Such a YeetContext.Provider is really the opposite, a YeetContext.Consumer. This is a concept that also exists natively in Live: it's a built-in component that can gather values from anywhere downstream in the tree, exactly like a Context in reverse. The associated useConsumer hook consumes a value instead of providing it.
The only difference between Yeet-Reduce and a Consumer data flow, is that a Consumer explicitly skips over all the nodes in between: it doesn't map-reduce upwards along the tree, it just stuffs collected values directly into one flat set. So if the reverse of a Consumer is a Context, then the reverse of Yeet-Reduce is Prop Drilling. Although unlike Prop Drilling, Yeet-Reduce requires no boilerplate, it just happens automatically, by rendering a built-in <Yeet … /> inside a <Gather> (array), <MultiGather> (struct-of-arrays) or <MapReduce> (any).
As an example of such a chain of expand-reduce-continuations, I built a basic HTML-like layout system, with a typical Absolute, Stack (Block) and Flex position model:
As I hover over components, the blue highlight shows which components were rendered by whom, while purple shows indirect, long-range data dependencies. In this video I'm not triggering any Live changes or re-renders. The inspector is external and implemented using vanilla React.
These particular layout components don't render anything themselves, rather, they yield lambdas that can perform layout. Once laid out, the result is applied to styled shapes. These styled shapes are themselves then aggregated together, so they can be drawn using a single draw call.
As I've demonstrated before, when you map-reduce lambdas, what you're really assembling incrementally is chunks of executable program code, which you can evaluate in an appropriate tree order to do all sorts of useful things. This includes generating GPU shaders on the fly: the bookkeeping needed to do so is mostly automatic, accomplished with hook dependencies, and by map-reducing the result over incremental sub-trees or sub-maps.
The actual shader linker itself is still plain old vanilla code: it isn't worth the overhead to try and apply these patterns at such a granular level. But for interactive code, which needs to respond to highly specific changes, it seems like a very good idea.
* * *
Most of all, I'm just having a lot of fun with this architecture. You may need a few years of labor in the front-end mines before you truly grok what the benefit is of structuring an entire application this way. It's a pretty simple value proposition tho: what if imgui, but limited to neither im nor gui?
The other day I was playing around with winit and wgpu in Rust, and I was struck by how weird it seemed that the code for setting up the window and device was entirely different whether I was initializing it, or responding to a resize. In my use.gpu prototype, the second type of code simply does not exist, except in the one place where it has to interface with a traditional <canvas>.
That is to say, I hope it's not just the React team that is taking notes, but the Unreal and Unity teams too: this post isn't really about JavaScript or TypeScript… it's about how you can make the CPU side run and execute similar to the GPU side, while retaining as much of the data as possible every time.
The CPU/GPU gap is just a client/server gap of a different nature. On the web, we learned years ago that having both sides be isomorphic can bring entirely unexpected benefits, which nevertheless seem absurdly obvious in hindsight.